Start here · The first step in AI security
You’re either shipping AI-built features every week or carrying ten years of old code.
Either way, you have the same problem: you don't know what path an attacker would take from the thing your team built to the thing your business can't afford to expose. The Mini AI Risk Map is the first step — ZIVIS maps one app, agent, automation, integration, or workflow, and shows what it touches, what it exposes, and what to fix first.
Start here before you buy a full audit, pen test, or AI red team.
Most teams don’t need to start with a massive security engagement. They need to start by seeing the system clearly: what it touches, where trust boundaries are crossed, what data or credentials are exposed, and which path creates the most business risk.
No giant audit. No vague AI governance deck. Just a clear map of your highest-risk path.
What it touches
Every system, user, data store, vendor, tool, and agent the feature can reach.
Trust boundaries
Where access crosses from trusted to untrusted — and where those lines are missing.
Risk exposure points
The places where access, data, credentials, integrations, or agent behavior create real exposure.
Highest-risk path
The single chain from entry point to business impact that matters most to fix first.
System map (illustrative only)
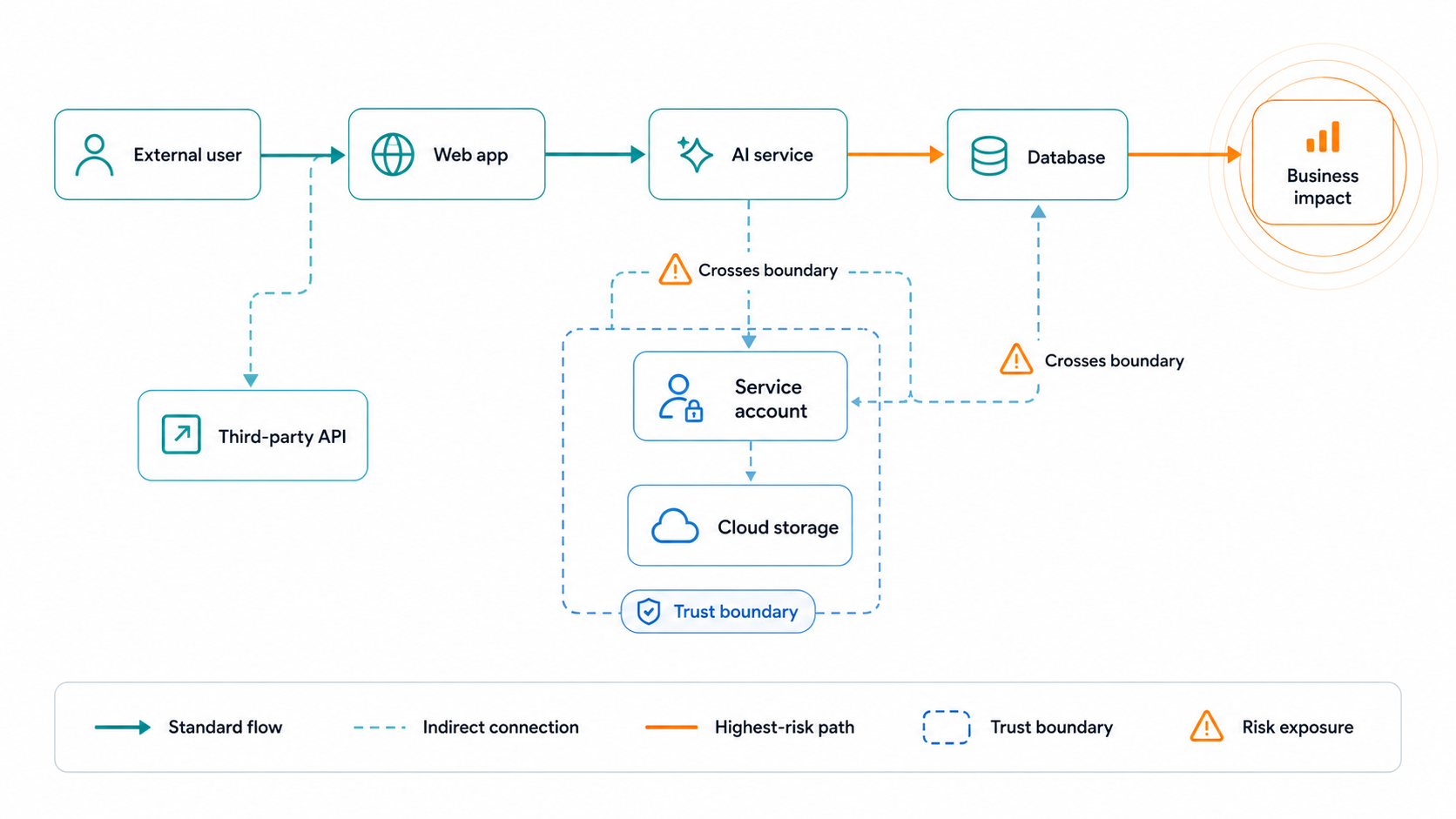
This is for you if…
You have a legacy app and AI is now being used around it.
“We don't know what this thing touches anymore.”
Someone built an internal automation, dashboard, or workflow with AI.
“It works, but I don't know if it's safe.”
Your team uses coding copilots but hasn't deployed an agentic system yet.
“We're not an AI company, but AI is in the way we build now.”
You don't have a real AppSec function.
“Security is owned by IT, engineering, or whoever has time.”
You're considering a pen test but aren't sure what to scope.
“We need to know where to look first.”
What you walk away with.
You’re not buying a report. You’re buying the first decision: where is the real risk, and what should we do next?
Touchpoint map
Systems, users, data, vendors, APIs, credentials, agents, automations, and the trust boundaries between them.
Highest-risk path
Entry point → exposed surface → chained weakness → trust boundary → crown jewel → business impact.
Prioritized fix list
What to fix now, what to monitor, and what can wait — ranked, not dumped.
Next-step recommendation
Stop here, fix internally, run a deeper audit, run AI red teaming, or move into continuous review.
Plus the critical findings we surface along the way.
The map isn’t theoretical. Walking the path almost always turns up real, already-present issues — the kind that have often been sitting there for years:
- Exposed secrets — API keys, tokens, and credentials sitting in code, config, or logs.
- Prompt-injection paths that let untrusted input drive privileged tools or agents.
- Over-permissioned agents and integrations with standing access to production data.
- Broken or missing trust boundaries between AI features and the systems they can reach.
- Sensitive data quietly flowing to third-party AI vendors.
- Unauthenticated or forgotten endpoints left exposed to the internet.
Why this is not just another scan.
A scanner gives you a list. ZIVIS shows how issues combine into a real business path — exposed data, broken trust boundaries, risky integrations, credential paths, agent and tool misuse, and impact your leadership team can actually understand.
01
Map what it touches
Systems, data, vendors, users, tools, and trust boundaries — the full reach of the feature.
02
Surface & cluster findings
We identify the issues and show which ones combine into real exposure — not a list to triage.
03
Explain the highest-risk path
A plain-English path from technical weakness to business consequence.
What customers say
The scanners weren’t wrong — they just couldn’t see the whole system.
I paid two pen test companies for separate scans and they turned up 2 findings (low and informational). I had ZIVIS for <24 hours and they found 45 critical findings that had likely been sitting there for years.
— CTO, healthcare technology company
Those findings didn’t come from running more scans. They came from mapping how the system actually connects — the exposed paths a scanner walks right past.
What we need from you
- One app, workflow, agent, automation, or integration to review.
- A short kickoff conversation.
- Architecture notes, repo access, screenshots, docs, or walkthroughs where available.
- One readout meeting with the people who need to make the decision.
We can work from messy reality. You don’t need a perfect architecture diagram to start.
What the Mini AI Risk Map is not
- A full penetration test.
- A compliance certification.
- A generic AI policy review.
- A 60-page PDF nobody reads.
- A replacement for deeper testing when the risk calls for it.
It’s the first map: what matters, why it matters, and where to go next.
Before you spend $10k+ or ignore the risk entirely…
…start by finding the path that actually matters. Send us the app, workflow, agent, automation, or integration you want mapped, and we’ll take it from there.
Mini AI Risk Map
$1,499
One use case · reviewed by humans
Find your highest-risk path.
A fast, deep read of your code, systems & architecture — reviewed by humans.
Buy nowKnow the app already? Buy now and we’ll schedule kickoff.